Reasoning and Learning
Reasoning and Learning Submission: Submit before 5:30pm 1 December via the submission link for assignment 2 on the subjects’ Moodle site.One ZIP file is···
Assignment 2: (10% of the total assessment in this subject) Reasoning and Learning
Submission: Submit before 5:30pm 1 December via the submission link for assignment 2 on the subjects’ Moodle site.
One ZIP file is to be submitted. The ZIP file is to contain: two source code files named:
The file main.pl is to contain your answer to question1 whereas the C or C++ file is to contain your answer to question2.
Important note: This assignment is individual work. Late submission and plagiarism will result in a penalty (refer to subject outline for details).
Question 1 (6 marks)
You are facing the following problem: You are given a robot and your task is to “guide” the robot through a 2-dimensional maze such that the robot can reach a desired goal state. Assume that the maze is defined as a regular 2-dimensional grid with discrete grid points. Some of the grid points can be visited by the robot while other grid points (such as those denoting walls and other obstacles) are off limit. Lets call the set of grid points that a robot can visit “states”. Assume that the following is given:
- A list of valid states (spaces that the robot can visit). It can be assumed that the list is complete and hence, the list defines the maze.
- A starting state. This defines the starting position of the robot.
- A goal state which defines the target state for the robot.
Your task is to write a rule called roby in Prolog. The rule is to find the shortest Reasoning and Learning
path from the given start state to the given goal state. The robot can take one step at a time and permitted are the moves up, left, right, and down. Diagonal movements are not allowed. This means that the robot can only move to states which are directly adjacent to a current state.
Your Prolog program is to read the list of states, the goal state, and the target state from a database containing “facts” called DB.pl.
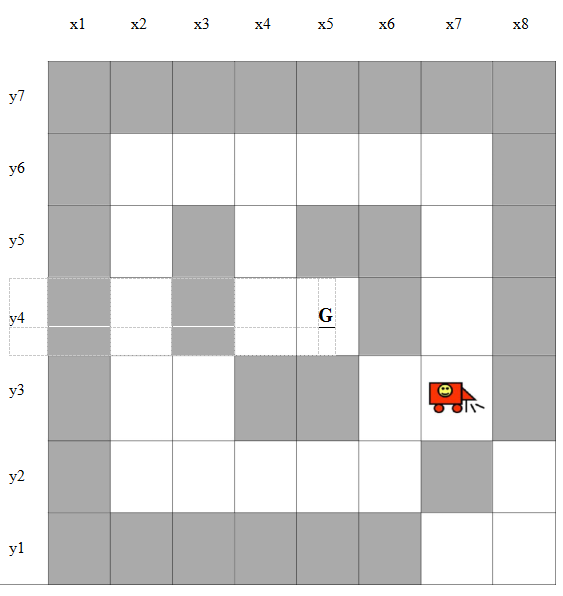
You are given the files DB.pl and main_template.pl. The file DB.pl contains a description of the maze which is shown on the next page. Your task is to:
- Extend the content of main_template.pl file such that is uses the facts as defined in plto compute the shortest path from the given start state to a given goal state. Your program should work correctly for any other maze, too.
- Use SWI Prolog to solve the task. Do not make use of additional libraries (your code must be stand-alone, without further dependencies).
- Ensure that your solution will work for other mazes, too. Your code will be tested on different versions of pl. Some of these mazes may not have a solution or may have more than one shortest paths (i.e. several solutions of the same length). Your program should produce a correct response (i.e. list all shortest paths, or should “fail” if there is no solution.
For example Reasoning and Learning
for the maze defined in the provided DB.pl your code should produce the following sequence as output:
s(7,3),s(7,4),s(7,5),s(7,6),s(6,6),s(5,6),s(4,6),s(4,5),s(4,4),s(5,4)
Note that some of the states in this maze are out of reach for this robot or, if the robot had started from s(8,1) then there would have been no solution.
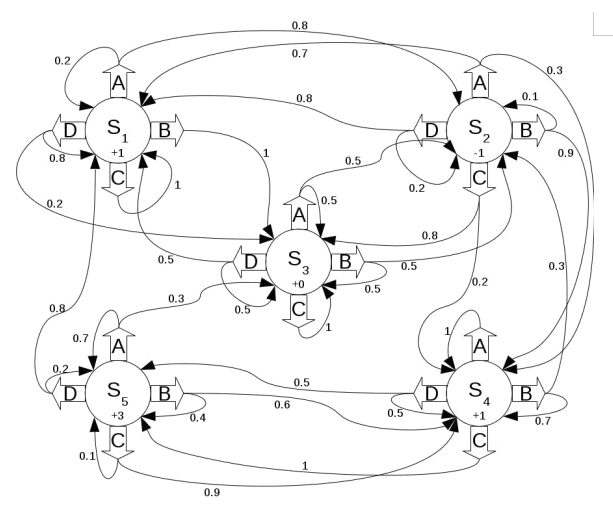
Question 2 (4 marks)
Implement the value iteration algorithm for MDP which computes the solution to the situation shown below. You may write your code in either C or C++. Your code must be implemented as a self-contained single source code file which does not require any additional libraries during compilation, does not require any additional data files during run-time, and does not expect any user inputs. For each value of k, your program is to print (to the screen) the reward vector J. Your program is to terminate when convergence is observed (use epsilon=0.0001). For
each time step k print the optimal policy. Use the discount factor .
Your name and student number should be in the comment header of the source code file.
第一题: Reasoning and Learning
您面临以下问题:
您将获得一个机器人,而您的任务是通过二维迷宫“引导”机器人,以使机器人可以达到所需的目标状态。假设迷宫定义为具有离散网格点的规则二维网格。机器人可以访问某些网格点,而其他网格点(例如表示墙壁和其他障碍物的网格点)则无法访问。让我们将机器人可以访问的一组网格点称为“状态”。假定给出以下内容:
- 有效状态(机器人可以访问的空间)列表。可以假定该列表是完整的,因此该列表定义了迷宫。
- 起始状态。这定义了机器人的起始位置。
- 定义机器人的目标状态的目标状态。
您的任务是在Prolog中编写一个称为roby的规则。规则是找到最短的
从给定的开始状态到给定的目标状态的路径。机器人一次只能执行一个步骤,并且可以向上,向左,向右和向下移动。不允许对角运动。这意味着机器人只能移动到与当前状态直接相邻的状态。
您的Prolog程序将从包含称为DB.pl的“事实”的数据库中读取状态列表,目标状态和目标状态。将为您提供文件DB.pl和main_template.pl。文件DB.pl包含迷宫的描述,这将在下一页显示。
您的任务是: Reasoning and Learning
- 扩展pl文件的内容,以便使用DB.pl中定义的事实来计算从给定开始状态到给定目标状态的最短路径。您的程序也应该可以在其他迷宫中正常工作。
- 使用SWI Prolog解决任务。不要使用其他库(您的代码必须是独立的,没有进一步的依赖关系)。
- 确保您的解决方案也适用于其他迷宫。您的代码将在不同版本的pl上进行测试。这些迷宫中的一些可能没有解决方案,或者可能有多个最短路径(即,多个相同长度的解决方案)。您的程序应产生正确的响应(即列出所有最短路径,如果没有解决方案,则应“失败”)。
第二题
为MDP实现值迭代算法,该算法计算针对以下情况的解决方案。 您可以用C或C ++编写代码。 您的代码必须实现为自包含的单一源代码文件,该文件在编译期间不需要任何其他库,在运行时不需要任何其他数据文件,并且不需要任何用户输入。 对于k的每个值,您的程序将在屏幕上打印奖励矢量J。观察到收敛时,程序将终止(使用epsilon = 0.0001)。 对于每个时间步长k,打印最佳策略。 使用折扣系数。
更多其他:代写作业 数学代写 物理代写 生物学代写 程序编程代写 加拿大代写被抓



