COMS 4771 HW3 (Spring 2022)
Machine Learning 机器学习作业代写 You can use any re-source publicly available to develop your regressor. (You don’t need to submit your code for this question.)
This homework is to be done alone. No late homeworks are allowed. To receive credit, a type-setted copy of the homework pdf must be uploaded to Gradescope by the due date. You must show your work to receive full credit. Discussing possible approaches for solutions for homework ques-tions is encouraged on the course discussion board and with your peers, but you must write your own individual solutions and not share your written work/code. You must cite all resources (includ-ing online material, books, articles, help taken from/given to specific individuals, etc.) you used to complete your work.
1 Combining multiple classifiers Machine Learning 机器学习作业代写
The concept of “wisdom-of-the-crowd” posits that collective knowledge of a group as expressed through their aggregated actions or opinions is superior to the decision of any one individual in the group. Here we will study a version of the “wisdom-of-the-crowd” for binary classifiers: how can one combine prediction outputs from multiple possibly low-quality binary classifiers to achieve an aggregate high-quality final output? Consider the following iterative procedure to combine classifier results.
Input:
– S – a set of training samples: S = {(x1, y1), . . . ,(xm, ym)}, where each yi∈ {−1, +1}
– T – number of iterations (also, number of classifiers to combine)
– F – a set of (possibly low-quality) classifiers. Each f ∈ F, is of the form f : X → {−1, +1}
Output:
– F – a set of selected classifiers {f1, . . . , fT }, where each fi ∈ F. Machine Learning 机器学习作业代写
– A – a set of combination weights {α1, . . . , αT }
Iterative Combination Procedure:
– Initialize distribution weights D1(i) =![]() [for i = 1, . . . , m]
[for i = 1, . . . , m]
– for t = 1, . . . , T do
– // ϵj is weighted error of j-th classifier w.r.t. Dt
– Define ϵj:= ![]() Dt(i) · 1[yi ̸=fj (xi)] [for each fj ∈ F]
Dt(i) · 1[yi ̸=fj (xi)] [for each fj ∈ F]
– // select the classifier with the smallest (weighted) error
– ft = arg minfj∈F ϵj
–ϵt = minfj∈F ϵj
– // recompute weights w.r.t. performance of ft
– Compute classifier weight αt =![]()
– Compute distribution weight Dt+1(i) = Dt(i) exp(−αtyift(xi))
– Normalize distribution weights Dt+1(i) = ![]()
– endfor
– return weights αt, and classifiers ft for t = 1, . . . , T.
Final Combined Prediction:
– For any test input x, define the aggregation function as: g(x) := ![]() , and return the pre-diction as sign(g(x)).
, and return the pre-diction as sign(g(x)).
We’ll prove the following statement: If for each iteration t there is some γt > 0 such that ϵt =![]() − γt (that is, assuming that at each iteration the error of the classifier ft is just γt better than random guessing), then error of the aggregate classifier
− γt (that is, assuming that at each iteration the error of the classifier ft is just γt better than random guessing), then error of the aggregate classifier
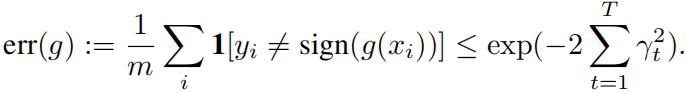
That is, the error of the aggregate classifier g decreases exponentially fast with the number of com-binations T!
(i) Let Zt := P i Dt+1(i) (i.e., Zt denotes the normalization constant for the weighted distribu-tion Dt+1). Show that
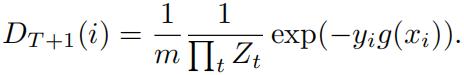
(ii) Show that error of the aggregate classifier g is upper bounded by the product of Zt: err(g) ≤ ![]() . Machine Learning 机器学习作业代写
. Machine Learning 机器学习作业代写
(hint: use the fact that 0-1 loss is upper bounded by exponential loss)
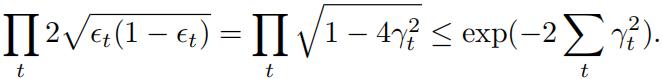
(iii) Show that Zt = .
(hint: noting Zt = ![]() , separate the expression for correctly and in-correctly classified cases and express it in terms of ϵt)
, separate the expression for correctly and in-correctly classified cases and express it in terms of ϵt)
(iv) By combining results from (ii) and (iii), we have that err(g) ≤ ![]() , now show that:
, now show that:
Thus establishing that err(g) ≤ exp(![]() ).
).

2 Estimating Model Parameters for Regression
Let Pβ be the probability distribution on Rd×R for the random pair(X, Y )(where X = (X1, . . . , Xd))
such that
X1, . . . , Xd∼iidN(0, 1),
and Y |X = x ∼ N(xTβ, ||x||2), x ∈ Rd
Here, β = (β1, . . . , βd) ∈ R d are the parameters of Pβ, and N(µ, σ2 ) denotes the Gaussian distri-bution with mean µ and variance σ2.
(i) Let (x1, y1), . . . ,(xn, yn) ∈ Rd × R be a given sample, and assume xi≠ 0 for all i = 1, . . . , n. Let fβ be the probability density for Pβ as defined above. Define Q : Rd → R by
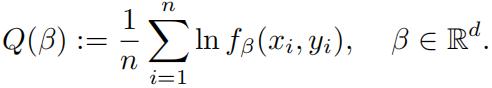
Write a convex optimization problem over the variables β = (β1, . . . , βd) ∈ Rd such that its optimal solutions are maximizers of Q over all vector of Euclidean length at most one.
(ii) Let (x1, y1), . . . ,(xn, yn) ∈ R d × R be a given sample, and assume xi ≠0 for all i =1, . . . , n. Let fβ be the probability density for Pβ as defined above. Define Q : Rd → R by
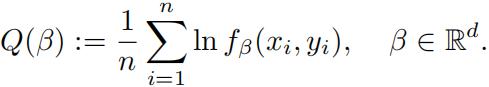
Find a system of linear equations Aβ = b over variables β = (β1 , . . . , βd) ∈ R d such that the solutions are maximizers of Q over all vectors in Rd .
3 Different learning rates for different strategies (Extra Credit)
Here will explore how the rate by which an algorithm learns a concept can change based on how labeled examples are obtained. For that we look at three settings: (i) an active learning setting where the algorithm has the luxury of specifying a data point and querying its label, (ii) a passive learning setting where labeled examples are drawn at random and (iii) an adversarial setting where training examples are given by an adversary that tries to make your life hard.
Consider a binary classification problem where each data point consists of d binary features. Let F be the hypothesis class of conjunctions of subsets of the d features and their negations. So for example one hypothesis could be f1(x) = x1 ∧ x2 ∧ ¬xd (where ∧ denotes the logical “and” and denotes the logical “not”). Another hypothesis could be f2(x) = ¬x3 ∧ x5. A conjunction in F cannot contain both xi and ¬xi . We assume a consistent learning scenario where there exists a hypothesis f∗∈ F that is consistent with the true label for all data points. Machine Learning 机器学习作业代写
(i) In the active learning setting, the learning algorithm can query the label of an unlabeled ex-ample. Assume that you can query any possible example. Show that, starting with a single positive example, you can exactly learn the true hypothesis f∗ using d queries.
(ii) In the passive learning setting, where the examples are drawn i.i.d. from an underlying fixed distribution D. How many examples are sufficient to guarantee a generalization error less than ϵ with probability ≥ 1 − δ?
3(iii) Show that if the training data is not representative of the underlying distribution, a consistent hypothesis f∗ can perform poorly. Specifically, assume that the true hypothesis f∗ is a con-junction of k out of the d features for some k > 0 and that all possible data points are equally likely. Show that there exists a training set of 2(d−k) unique examples and a hypothesis f that is consistent with this training set but achieves a classification error ≥ 50% when tested on all possible data points.
4 Regression Competition! Machine Learning 机器学习作业代写
You’ll compete with your classmates on designing a good quality regressor for a large scale dataset.
(i) Signup on http://www.kaggle.com with your columbia email address.
(ii) Visit the COMS 4771 competition:
https://www.kaggle.com/c/coms4771-spring-2022-regression-competition/
You shall develop a regressor for a large-scale dataset available there. You can use any re-source publicly available to develop your regressor. (You don’t need to submit your code for this question.) Machine Learning 机器学习作业代写
(iii) Your pdf writeup should describe the design for your regressor: What preprocessing tech-niques and regressor you used? Why you made these choices? What resources you used and were helpful? What worked and what didn’t work?
Make sure cite all the resources that you used.
Evaluation criterion:
- You must use your UNI as your team name in order to get points. For example:
- If your uni is abc123 then your teamname should be: abc123
- You must get a Mean Absolute Error (MAE) score of at most 500 on the private holdout test-dataset to get full credit. (This involves employing sound ML principles in the design and selection of your best performing model.)
- Extra points will be awarded to the top ranked participants, using the following scoring mechanism:

更多代写:澳大利亚cs代写 proctoru如何作弊 北美exam代考推荐 北美代写essay 加拿大mba论文代写 论文主题
合作平台:essay代写 论文代写 写手招聘 英国留学生代写