Module title: FIN30290 Recent Research Topics in Finance
Group assignment title: Bank telemarketing and machine learning
北美金融essay代写 You should work in a group, of circa 5 students, and each group should nominate an individual to submit a single project report.
Instructions
You should work in a group, of circa 5 students, and each group should nominate an individual to submit a single project report. Maximum word-count for the report is 3,000 words.Front page of submitted assignment should detail module title, membership of the group (i.e.,students’ names and numbers) as well as the assignment title, and the assignment word count.
Please submit this project by Friday, May 6 via Brightspace ‘Assessment’ and the‘Assignment’ Project. In addition, email your report and program code to: cc: . State ‘BSc Group Assignment: Bank telemarketing and machine learning’ in the subject of the mail, and cc: all group members. Please do not collaborate, in this assignment, across groups.
Assessment and grades 北美金融essay代写
You will be assessed on your ability to respond to questions raised below, i.e., to use machine learning informed alert model algorithms, critically evaluate the performance of these methods, and coherently report your findings. This project counts for 40% of your overall module grade.

Assignment Context
An important source of income at banks is the term deposit, i.e., deposits by customers at a fixed rate for a fixed time. This capital can be used to disburse loans at a higher interest rate.The bank, hence, uses marketing techniques to target customers to save via term deposits. For example: email, advertisement, telephonic and digital marketing. Telephonic marketing (i.e.,phone calls) remains an effective way to acquire term deposit customers, especially if enabled with machine learning. Banks can use data and machine learning informed alert models to identify customers who are more likely to save via a term deposit, and to inform a telephonic marketing campaign accordingly.
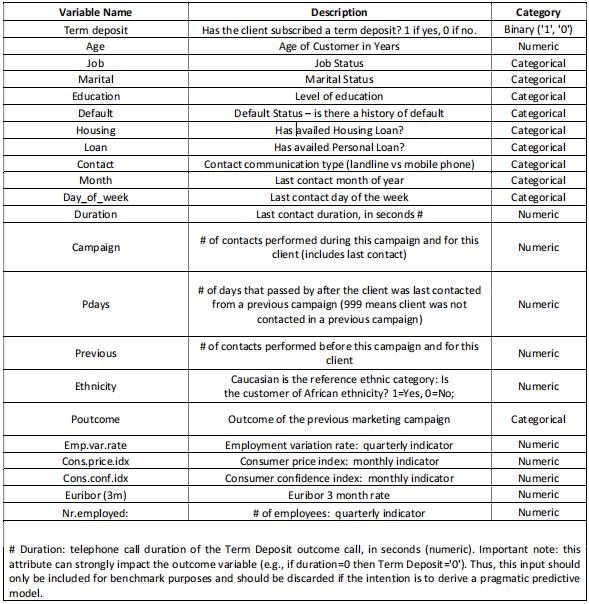
The dataset, in this assignment, is related to the direct telemarketing campaigns (phone calls) of a European banking institution. You can find the data for the project on Brightspace(MyLearning \ Group Assignment) and variable descriptions below.The classification goal is to predict if the customer will subscribe to a term deposit (Term
1 Word count includes an assignment’s references section.
Deposit = 1). Tapping into the repertoire of your Machine Learning modelling, evaluation and deployment knowledge, provide recommendations to the bank’s Retail Marketing department to achieve its goal.
Questions 北美金融essay代写
1.(a) Fit a logistic regression model on the dataset. Choose a probability of default threshold of 1 0 % , 20%, 35% and 50%, to assign an observation to the Term Deposit = 1 class.Compute a confusion matrix for each of the models. How do the True Positive and False Positive rates vary over these models? Which model would you choose?
(b) Divide the dataset into training (70%) and test (30%) sets and repeat the above question and report the performance of these models on the test set.
(c) Plot the ROC for a logistic model on a graph and compute the AUC. Explain the information conveyed by the ROC and the AUC metrics.[8 marks]
2.(a) Fit classification tree, bagging and random forest models on the dataset and comment onthe performance of these models. Do you think we are overestimating the performance of these models by fitting them on to the whole dataset? If so, state your reasons.
(b) Split the dataset in two parts: training (70%) and test sets (30%). Fit the models on the training dataset and evaluate their performance on the test set. Which model would you choose and why?
(c) For the best model chosen, rank and plot predictors according to their predictive power. 北美金融essay代写
(d)How do these models perform compared to the model in question 1?[9 marks]
3.(a) Standardize your predictors and fit KNN classifier with K equal to 1, 3, 5 and 10, respectively.Evaluate the performance of these models on the test set.
(b) How do these models perform compared to the tree-based models in question 2 and logistic model of question 1? [8 marks]
4.(a) Fit at least one other binary classifier (e.g. a linear probability model or a Support Vector Machine classifier) to the dataset. Describe its performance relative to the classifiers highlighted above.
(b) Is your training dataset balanced? Comment on the drawbacks of fitting a Machine Learning technique on an unbalanced dataset. Can you identify and deploy a technique to address this concern? If so, why do you think that the method(s) could work? Hint: It is up to each student group to search for a systematic understanding and solution to the phenomenon of imbalanced data.[15 marks]
Description of the Dataset
更多代写:法律学作业代写 sat代考 代做政治学作业 北美论文代写essay 北美留学生report报告写作 paraphrase软件
合作平台:essay代写 论文代写 写手招聘 英国留学生代写


