CS 4100: Artifificial Intelligence (Fall 2022)
Problem Set #4: Reinforcement Learning
代写AI作业 If you write your answers on paper and submit images of them, that is fifine, but please put and order them correctly in a single .pdf fifile.
Please remember the following policies:
- Exercises are due at 11:59 PM Boston time (ET). See Canvas for the current most up-to-date deadline.
- Submissions should be made electronically on Gradescope.
You can make as many submissions as you wish, but only the latest one will be considered, and late days will be computed based on the latest submission.
- See the late policy in the syllabus.
- Solutions may be handwritten or typeset. For the former, please ensure handwriting is legible. If you write your answers on paper and submit images of them, that is fifine, but please put and order them correctly in a single .pdf fifile. One way to do this is putting them in a Word document and saving as a PDF fifile.
- You are welcome to discuss these problems with other students in the class, but you must understand and write up the solution yourself, and indicate who you discussed with (if any). 代写AI作业
- For questions about the problem set, please use Piazza or come to offiffiffice hours.
1.35 Points Model-based RL. Consider the following MDP, where each edge is labeled with its action (transition probabilities and rewards are unlabeled and will be learned from data):
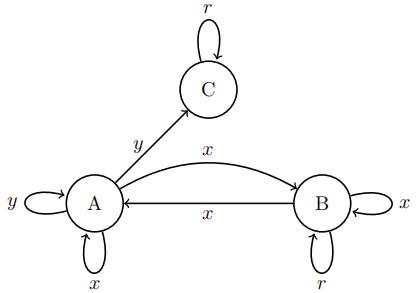
(a) Suppose you observe the following transitions, where s is the initial state, a is the observed action, s 0 is the state that was transitioned into, and r is the reward:

Give the learned reward and probability for each (s, a, s0 , r).
(b) Using the parameters learned in the previous step, perform 2 steps of value iteration (using a discount of γ = 0.9).
(c) Give the optimal policy π ∗ according to the 3 steps of value iteration you just performed.
(d) Suppose you can gather 5 more data points to learn more information about this MDP. The way you gather a new data point is to pick a particular state and action to perform (for instance, “perform action y in state A”). Which 5 more data points would you choose, and why? (There are many valid choices here. Provide justifification for any choice that you make.)
2.(30 points) Model-free reinforcement learning 代写AI作业
(a) In this question we will perform model-free policy-evaluation using temporal difffferencing. Assume we have the following value estimates for some policy π whose value we wish to update:
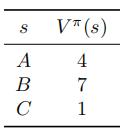
Suppose the agent is in state A, takes action π(A), enters state B, and receives reward +4. Using the temporal difffference update rule with a learning rate of α = 0.1 and discount γ = 0.9, update the values in the above table to take into account this new observation.
(b) Suppose the agent gets stuck in an infifinite loop where it repeatedly observes the same transition as in the previous question, again with a learning rate of α = 0.1 and discount γ = 0.9. In the long-run, what value will each V π (s) converge to?
(c) Assume we have the following Q-value estimates:

Suppose the agent is in state A, takes action b, transitions to state B, and gets a reward of +2. Give the updated Q-values that result from Q-learning upon observing this transition, again using learning-rate α = 0.1 and discount-rate γ = 0.9.

3. 35 points. Feature representation for approximate Q-learning.
Consider the following scenario: We would like to use a Q-learning agent for Pacman, but the state space for a large grid is too massive to hold in memory. To solve this, we will switch to feature-based representation of the Pacman game state, where we assume that Q(s, a) can be expressed as a (weighted) linear combination of state-action features:
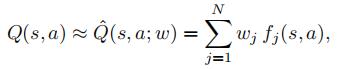 (1)
(1)
where wj are real-valued weights and fj (s, a) are functions called features.
(a) Suppose we design two features to represent the state: fg(s, a) is 1 if there is a ghost within one square of where PacMan is after executing the action and 0 otherwise, and fp(s, a) is 1 if there is a food pellet within one square of PacMan after executing the action and 0 otherwise.
Give the evaluation of fg and fp for the following state for the action “move up”:

(b) Suppose (s, a; w) = wgfg(s, a) + wpfp(s, a), and that wg = −2 and wp = 10. Compute (s, a; w) for the above PacMan state for the action “move up”.
(s, a; w) = wgfg(s, a) + wpfp(s, a), and that wg = −2 and wp = 10. Compute (s, a; w) for the above PacMan state for the action “move up”.
(c) Now we will use a variant of Q-learning to update the weights for each feature upon observing a particular transition. The feature-based Q-learning update rule is:
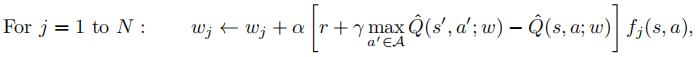 (2)
(2)
Where s is the initial state, s 0 is the state transitioned into, a is the observed action, and r is the observed reward. I.e., we update each weight one at a time, based on whether that feature is present in the state.Assume wg = −2 and wp = 10, γ = 0.9 and α = 0.1. Suppose PacMan begins in the game state above,executes the action “move up”, and experiences a reward of +0. Use Eq. 2 to compute the new values of wg and wp (Note: the new values might be the same as the old values in some cases).
(d) We can show that feature-based Q-learning is a generalization of the tabular case we have been studying. 代写AI作业
Suppose we have the following Q-value table:
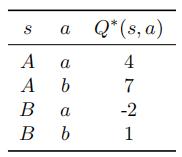
Give a set of features fj and weights wj such that Q(s, a; w) = Q∗ (s, a).
Hint: You can use as many features and weights as you like.
更多代写:assignment商科作业代写 ap考试代考 Chemistry化学网课exam代考 ENGL英语论文代写 dissertation代寫价格 代写应用统计作业
合作平台:essay代写 论文代写 写手招聘 英国留学生代写