Numerical Computing, Spring 2022
数值计算作业代写 The previous question was the special case λ = 1. Change your code to search for solutions to this more general ODE, for any given λ ≥ 1
Homework Assignment 8 数值计算作业代写
1.This question concerns polynomial interpolation using the Lagrange formula as well as cubic spline interpolation.
(a)Writetwo matlab functions to implement the barycentric version of the Lagrange interpolation algorithm given in AG, 11,434. The first function, baryConstruct, should computethe barycentricweights for the n+1 interpolation data points (xi, yi), i = 0, . . . , n (since matlab does not allow zero indexing, you should shift all indexes given here up by one).
The second func- tion, baryEval, should evaluate the resulting polynomial, which has degree n, on a fine grid of points zj, j = 0, . . . , N , where N is much larger than n. Be sure to check whether zj equals any of the interpolation points xi before applying the evaluation formula, as otherwise the result will be NaN; in this case, simply set the result to yi. 数值计算作业代写
(b)Test your code on the case that the xiare the 11 equally spaced points from −1 to 1 (including the end points) and yi = f (xi), where f is the Runge1 function (AG Example 6, p. 445) defined by
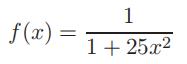
and the zj are 101 equally spaced points from −1 to 1 (again including the end points). Plot both the interpolation points (xi, yi) using, say, plot(x,y,’r*’) and the polynomial evaluated on the zj with, say, plot(z,pz,’.’) or plot(z,pz,’-’), in the same figure, as well as the Runge function itself evaluated on the zj. As usual, use legend to show which plots are which. Also, in
1 A little trivia item is that Runge was Richard Courant’s father-in-law. Courant died before I came to NYU, but I did meet his widow, Runge’s daughter, when she was 99.
the same figure, plot the cubic spline interpolating the same 11 interpolation points, obtained using matlab’s spline function, called with, say, sz = spline(x,y,z), which uses the default not-a-knot conditions (see AG p. 469). 数值计算作业代写
(c)Finally, in a new figure, plot the Runge function again and call the two-input-argument variant of spline on the same (x, y) data like this: pp=spline(x,y). The resulting field coefs gives you the cubic spline coefficients for all 10 cubic polynomials making up the spline. Using polyval, plot each of these cubics on all the zjpoints from −1 to 1, each in a different color (although matlab has only 7 default non-white colors, you can get more by providing ’Color’,[r g b] to the plot command). Indicate which part of each cubic coincides with the spline by overwriting it suitably, perhaps using the ’–k’ symbol (dashed black line).

2.Thisquestion concerns the BVP ODEs discussed in AG, 3, p. 94 and Chap. 9, p. 320. 数值计算作业代写
(a)Let v be a smooth function mapping t ∈ R to R. The Taylorseries expansion of v around a point t is, assuming h > 0 is small,
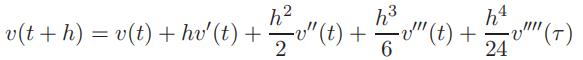
where the quantity τ in the final “remainder” term is some point in [t, t + h]. Using this and the analogous equation for v(t − h), obtain the formula that we discussed in class (see also AG, p. 94), approximating the second derivative v′′(t) in terms of v(t), v(t + h) and v(t − h). Also, explain why the error of this approximation is O(h2). It may be helpful to recall the central difference quotient discussed at the end of Chapter 11 of my book, but that was for approximating the first derivative, not the second derivative.
(b)Now,as discussed in AG, Chap. 9, p. 320, let’s consider the non- linear ODE
![]()
for t in the interval [0, 1], with boundary conditions v(0) = 0, v(1) = 0. 数值计算作业代写
This ODE is called second-order because it involves the second derivative of v and it is called a boundary value prob- lem (BVP) because the boundary conditions are specified at both end points of the interval. Here v maps [0, 1] to R and t is a space dimension, not time; it would be more conventional to write x instead of t but that could cause confusion with the x notation usually used in nonlinear systems g(x) = 0. Let us subdivide the interval [0, 1] into N equal subintervals and set ti = ih, i = 0, 1, . . . , N , where h = 1/N .
We then look for an approximate solution vi ≈ v(ti), i = 1, . . . , N − 1, to the ODE, using the answer to the previous part to approximate v′′(ti) and imposing the boundary conditions by setting v0 = vN = 0. This gives a system of N − 1 nonlinear equations in the N − 1 variables v1, . . . , vN−1, given by g(v) on AG p. 320, with Jacobian matrix J(v) given by the tridiagonal matrix on AG p. 320.
Write a program to search for solutions of the nonlinear system using Newton’s method, fixing N = 100.
Represent the Jacobian J(v) as a sparse matrix, and use \ to solve the linear system in Newton’s method. Let’s denote the iterates generated by New- ton’s method as v(k), k = 1, 2, . . ., and terminate the loop when “g(v(k))”2 is less than a given tolerance, say 10−10. Set the initial iterate v(0) to the vector given near the bottom of AG p. 320, trying several different choices of α. 数值计算作业代写
You should be able to find both solutions to the ODE given in Fig 9.3 on the next page (but no matter how hard you look, you won’t find more: that’s all there are). Since some choices of α will result in Newton’s method diverging, be sure to limit the number of iterations to some reasonable maximum number such as 50. For each of the two solutions to the ODE, choose one of the starting points that led to this solution and plot a figure showing all the Newton it- erates (although you won’t be able to distinguish the last few), and also print a table showing “g(v(k))”2, k = 1, 2, . . .. Do you observe quadratic convergence? If not, you probably have a bug.
3.Now let λ ≥ 1 be given, and consider the differentialequation 数值计算作业代写
![]()
The previous question was the special case λ = 1. Change your code to search for solutions to this more general ODE, for any given λ ≥ 1, modifying the formulas for the function g(v) and the Jacobian J(v) accordingly. As you increase λ from 1, how do the two solutions to the ODE change? Answer this by plotting them for a few values of λ that you choose, labelling the plots accordingly. You will find that for λ larger than a critical value λ∗, there are no solutions.
Find a way to automate your code so that it tells you, for any given λ, whether there are 2 solutions or no solutions, and then use the bisection method on λ to find this critical value λ∗ to as many digits as you can in a reasonable amount of time. How many solutions do you think there are for λ = λ∗? Explain your reasoning.
4.Implementthe gradient and Newton methods for minimizing a convex function f . This is much simpler than you might think from reading AG sec 9.3, where much of the discussion is about what to do if f is not convex.
Optimization of Convex Functions
Start with x(0), and set σ ∈ (0, 0.5), β ∈ (0, 1).
for k = 0, 1, 2, . . .
Either
(Gradient descent direction) Set p(k) = −∇f (x(k))
or
(Newton descent direction) Set p(k) to be the solution of ∇2f (x(k))p(k) = −∇f (x(k)) 数值计算作业代写
(Backtracking line search)
Set t = 1
while f (x(k) + tp(k)) > f (x(k)) + σ t ∇f (x(k))T p(k) do
t ← βt
set x(k+1) = x(k) + tp(k)
Implement this in a matlab function convopt, passing f to convopt as an anonymous function which means that calls to evaluate the func- tion and gradient (and Hessian for Newton’s method) inside convopt will actually be to some function whose name is unknown until convopt is called. For the line search parameters, use σ = 0.1, β = 0.5.
Then use this function for f :
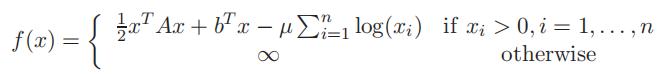
where A is an n × n symmetric, positive definite matrix and µ > 0. The gradient of the quadratic term 1 xT Ax + bT x is simply Ax + b, and its Hessian is A. The log function is the natural logarithm, so the derivative of log(xi) is ![]() , and the second derivative is
, and the second derivative is ![]() . Since the log is not defined for zero or negative numbers, we set f to ∞ (using inf) if any of the xi are zero or negative, and since the gradient is not defined in this case, you can set it to a vector of nan’s.
. Since the log is not defined for zero or negative numbers, we set f to ∞ (using inf) if any of the xi are zero or negative, and since the gradient is not defined in this case, you can set it to a vector of nan’s.
Note that since log(xi) goes to −∞ as any xi approaches zero, because of the minus sign, f (x) increases towards ∞ if any xi approaches zero.
We say that the function f maps Rn to the “extended reals” R ∪ {∞}. Set the initial iterate x(0) to the vector of all ones. Since this is in the “positive orthant” Rn , meaning the set of vectors with strictly positive components, the line search will ensure that subsequent iterates remain in Rn . 数值计算作业代写
Using this data, run the gradient and Newton methods with µ = 1, terminating them after 100 iterations or when the norm of the gradi- ent is very small, perhaps 10−10. Plot the gradient norms ||∇f (x(k))||, k = 0, 1, 2, . . ., for both methods in the same figure using semilogy. Is there a big difference between their behavior? Do you observe quadratic convergence of the gradient norms for Newton’s method? If not, you probably have a bug.
Then repeat for µ = 10−6. Are the comparative results much different? To guess why, take a look at the condition number of the Hessian ∇2f (x) at the final iterate, which is the ratio of its largest and smallest eigenvalues, equivalently its singu- lar values, since the Hessian is symmetric and positive definite, which you can compute from eig or svd, and compare these for the two different values of µ.
更多代写:北美商科代修网课 托福代考台灣 代看网课 出国留学个人陈述PS代写 毕业论文Methodology代写 代写自传
合作平台:essay代写 论文代写 写手招聘 英国留学生代写



