MLB Player Digital Engagement Forecasting
代写商业分析论文 Baseball fans get information about players through all kinds of media, and who they will search depends on some factors.
Problem
The purpose of this project is to predict how fans engage with MLB players’ digital content on a daily basis for a future date range. It’s a problem related to time series forecasting.
Baseball has been number-driven from an early age. Baseball fans get information about players through all kinds of media, and who they will search depends on some factors. As a result, it is important for MLB to figure out and understand these factors in order to create deeper relationships between players and fans and provide a new experience for fans.
The dataset is taken from kaggle contest sponsored by Google Cloud and MLB.
Dataset 代写商业分析论文
Our target is 4 different measurement of engagement(target1- target4). Since it is a time series forecasting problem, daily data (train.csv) is provided. Also, a set of static files that do not change with time (players.csv, teams.csv, seasons.csv, awards.csv) are also included in this project. The size of the entire data is about 4Gb.
At last, during the Evaluation phase, the test set will be a future in-season range of approximately one month.
The data in available as 4 tables:
- csv – the training set.
- csv – an example in the form of the test set that you’ll be evaluated on.
- csv – A sample submission file in the correct format based on the example test set.
- csv – A collection of awards given out prior to 01/01/2018 (the first date in train.csv). 代写商业分析论文
- csv – Library containing high level information about all MLB players in this dataset.
- csv – Information about start and end dates of all seasons in this dataset.
- csv – Library containing high level information about all MLB teams.
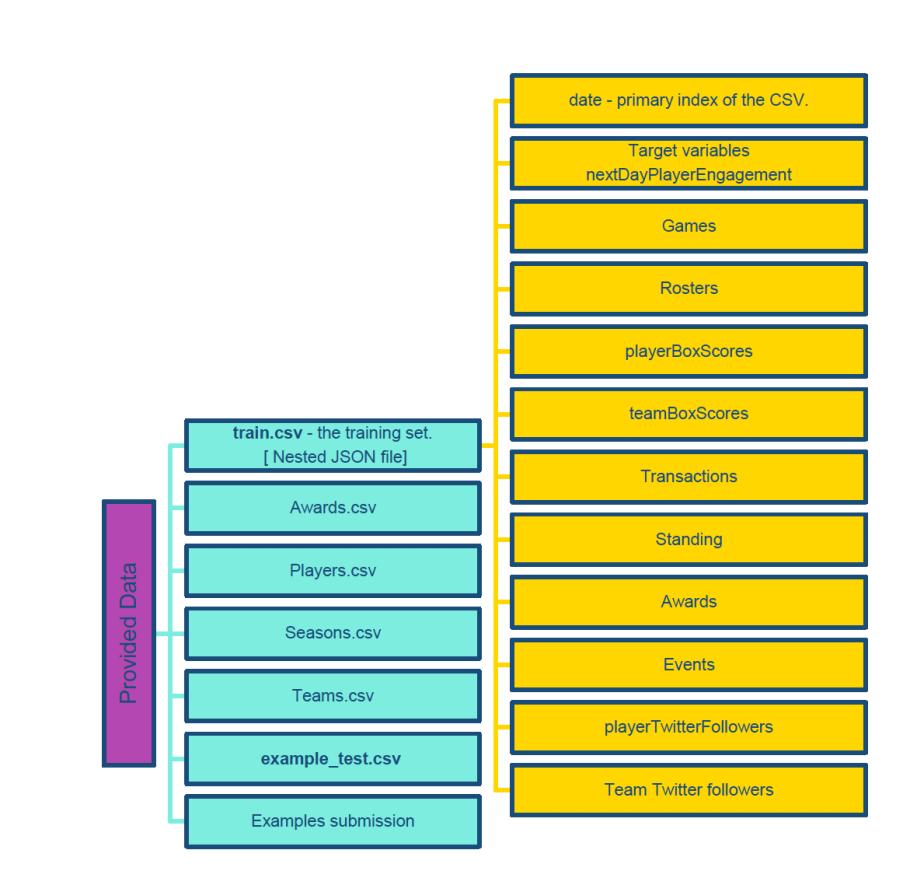
In these datasets, train.csv is the main dataset we used to train the model, and it is a nested JSON file. It contains the following information.
- date primary index of the CSV.
- nextDayPlayerEngagement [Nested JSON containing all modeling targets from the following day.]
- Games [32 features + 639 observations]
- Rosters [05 features + 1216 observations]
- playerBoxScores [83 features + 538 observations]
- teamBoxScores [57 features + 538 observations]
- Transactions [13 features + 1103 observations]
- Standings [46 features + 531 observations]
- awards [07 features + 294 observations]
- events [71 features + 536 observations]
- playerTwitterFollowers [06 features + 40 observations]
- teamTwitterFollowers [06 features + 40 observations]
Exploratory Data Analysis
Between Targets
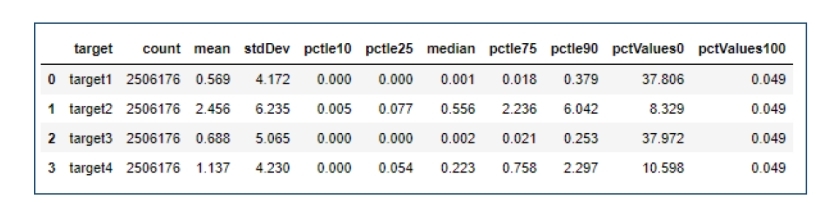
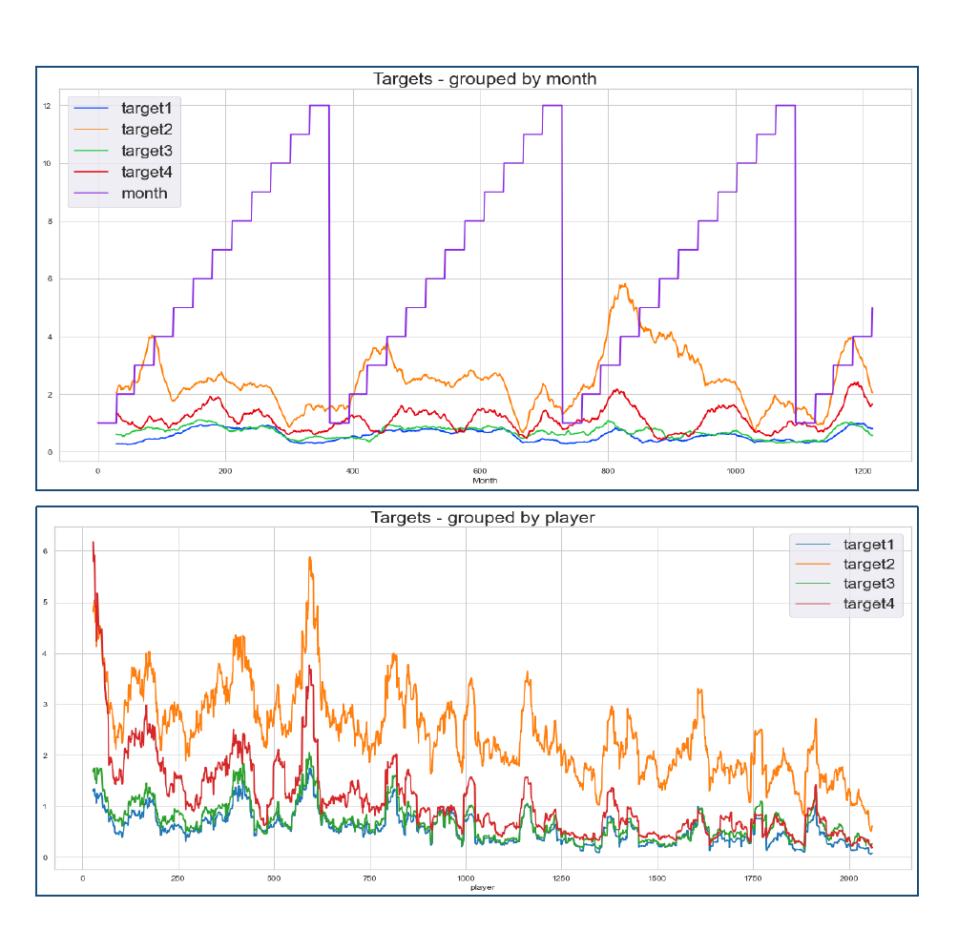
At this time, we focused on the analysis of the targets. The four targets in the train.csv is included in the nextDayPlayerEngagement, which specifically containes Time series dataset in long format, 2061 players with player IDs, 1216 days (Jan 1st ,2018 to Apr 30th, 2021, Total data points = 2061*1216 = 2506176 and 4 target variables.
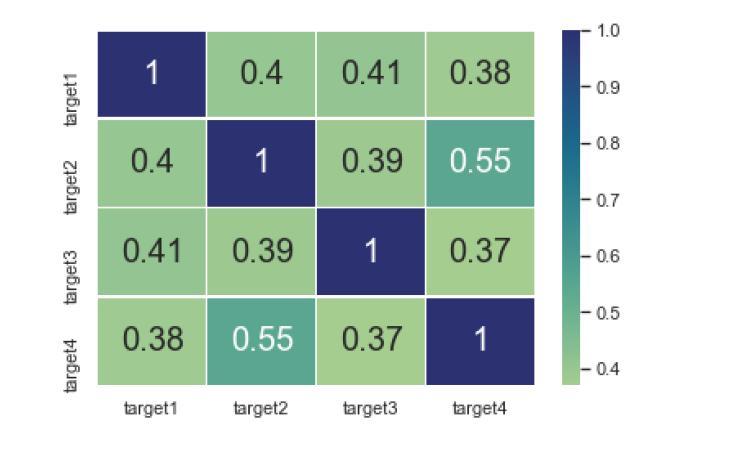
From their correlation analysis, the correlation between the four targets is not very high, indicating that the choice of targets is reasonable and can reflect the fans engagement from different aspects.
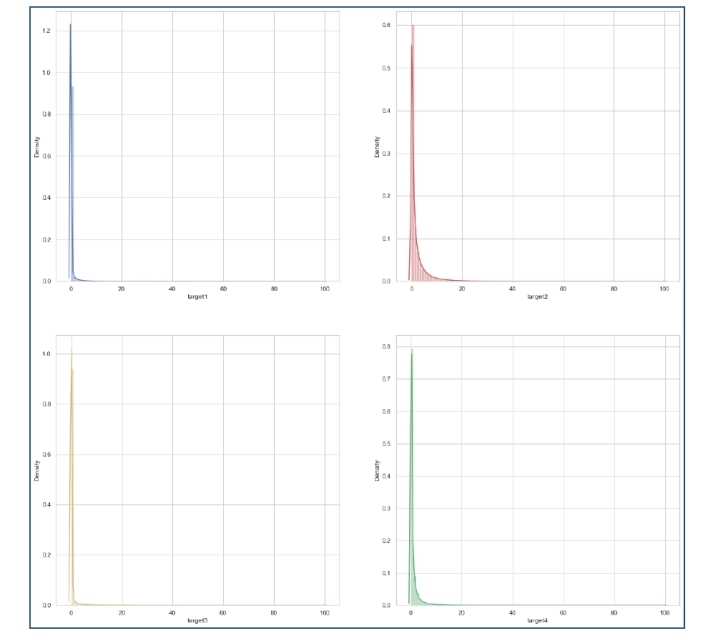
Then when we focus on the distribution of 4 target, we found that they are biased,skewed to the right side. Obviously the low score is far more than high score, which is severe for target1 and target3.
Then we grouped the targets by month. Obviously, we found that the target2 has a peak in March and April every year, and a gap in October and December, which means that the target2 time series is periodical and has a seasonal pattern. 代写商业分析论文
When grouped by player, target2 is obviously higher than the other 3 targets, and the value of 4 targets are consistent– when player1 has higher score of target1 than player2, the player1’s value of other 3 targets will be also higher than player2.
Between Target and Variables
In this part, we did a rudimentary exploratory analysis of how various single factors relate to digital engagement individually, just to provide a baseline of how these relationships might be explored.
Based on the target averages in different levels of factors, we can have some following findings. 代写商业分析论文
- For different player-related factors (team/roster/transactions)
- Well-known stars like Mike Trout and Aaron Judge stand out with digital engagement averages of 17-25, much higher than the overall average across all players.
- Players on some traditionally popular teams – Yankees, Dodgers, Red Sox – have had higher digital engagement averages
- Among roster status categories with significant sample size, ‘active’ players have the highest average digital engagement (as expected).
- On average, traded players have much higher digital engagement right after the trade then players who are signed as free agents
- Players with previous MVPs and Cy Young Awards tend to have much higher average digital engagement.
2.For different player game info-related variables
- Players in the All-Star Game (gameType = ‘A’) have had pretty high digital engagement on the day after that game.
- Outside of the All-Star teams, players playing in games (not just on the roster) for the Yankees, Dodgers, and Cubs have the highest digital engagement averages.
- The average digital engagement by game opponent list looks a good bit different, and has a bunch of teams clustered by division (e.g. all AL East teams up top, all AL Central teams at the bottom). This suggests that this could just be a byproduct of popularity of the teams that play those opponents more, since MLB teams play division opponents much more often than others.
- The effect isn’t huge, but players whose teams won the day before tend to have higher digital engagement averages than those on losing teams. 代写商业分析论文
3.For different player game pitching-related stats
- Pitchers who start tend to have higher engagement than other players, with more than double the digital engagement (on average) if they record a win (vs a loss or no-decision).
- The few pitchers who have thrown shutouts in this span have averaged very high digital engagement numbers the next day.
- The 8 individual no-hitters in this span have resulted in player digital engagement numbers close to the max – an average of ~85 across all targets (on a 0-100 scale)! Other complete games (still pretty rare) having a pretty high average as well, near 15.
4.Correlation coefficients of some continuous variables and target metrics
- Many of these stats/metrics, particularly the few pitching ones chosen here, have pretty low pairwise correlations with digital engagement.
- There is a weak-to-moderate positive correlation between some basic hitting statistics that can take on a range of values on a day (plate appearances, hits, total bases) and digital engagement.
- There are some relatively weak correlations with team performance. Players on teams with higher win percentage or better league rank (lower is better) tend to have higher digital engagement, but the magnitude of the correlation is quite small.
- Players with more previous All-Star appearances and Twitter followers, and those on teams with higher followings on Twitter, tend to have higher average digital engagement. These are some of the stronger correlations among the factors considered here.

Takeaways
From the analysis we can conclude the following:
- All the 4 targets are skewed and should be transformed to the logarithmic scale so that the distribution isn’t as skewed
- The analysis between target and features are really rudimentary. There is a lot to be analyzed further about which of these factors might matter more/less when used together to predict digital engagement, as well as the causal mechanisms by which these factors affect the targets.
Data Preprocessing 代写商业分析论文
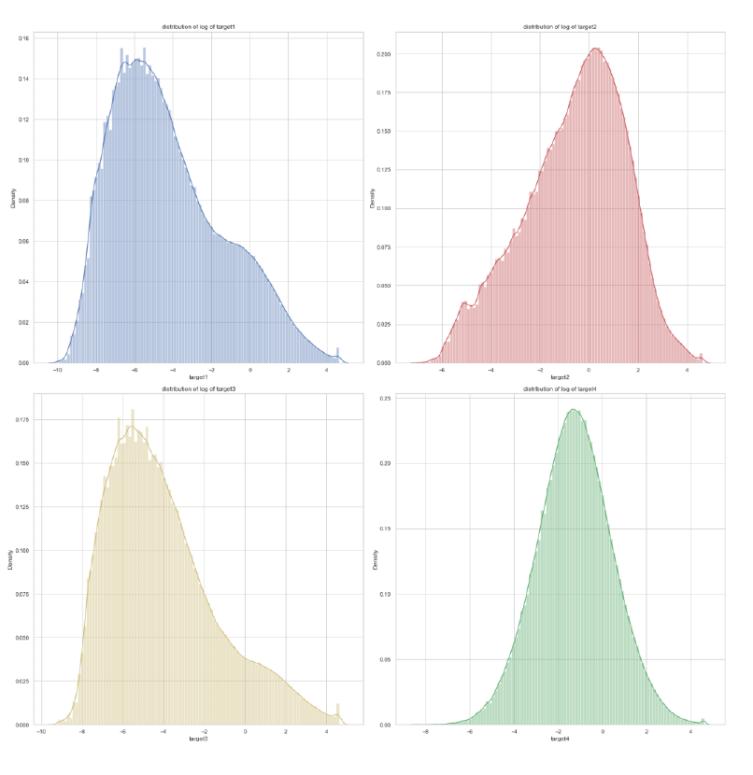
Target Transformation
From the analysis above, we knew that the distributions of the 4 targets are skewed to the right side. In order to build a better model, we did the log transformation to these target to get a approximately normal distribution. After the transformation, we can see that the distributions of the targets seem like the following figures.
Feature Engineering 代写商业分析论文
In order to combine the information from different dataset and select the features that are really needed in our model, we implemented some feature engineering in the original dataset. To be more specific, we conducted the following steps to clean up and organize the data.
- Reorganize the dataset and join the datasets.
- Added features from other datasets, such as Holidays, Weekends, Days since last game, Break in Winning streak, Break in loosing streak and so on.
- Turn all the data to the player-date level. For example in the games table, firstly we change it into 1 row per team game, then merge with team box scores. Then aggregate player game-level stats to daily date, and merge date-level player game stats with date-level player stats from events.
- Join and merge all the player-date level data into one dataset as the Player Daily Engagement
2.One-hot encoding.
- Encode the categorical variables into several binary variables. For example, the value of rosterStatusCode has 11 categories, such as A, BRV and D10. After One-hot encoding, there are 11 variables related to this code in total. If the category is A, rosterStatusCode_A is 1 and other 10 variables are 10
- In this way, we could use numerical variable in our model.
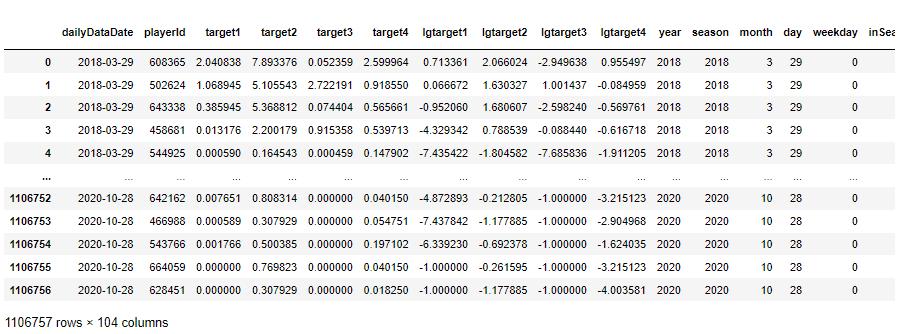
- Final dataset:
- As a result, we got 104 variables in total, including 100 features and 4 targets. There are 1106757 observations in the training dataset. The specific features are shown in the following list.

Other than the issues highlighted the data is mostly clean.
Machine Learning Models
Training Strategy
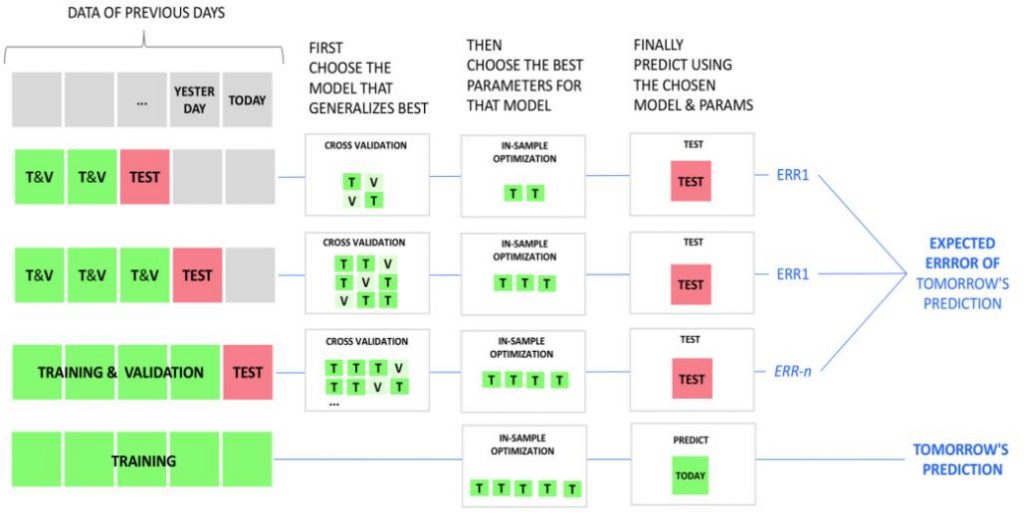
We used the sklearn timeseriesSplit to split the dataset into training dataset and testing dataset. The training part take the data from 01/01/18 to 03/31/2021. The testing data is from 04/01/2021 to 04/30/2021, including 2061 players and 30 days, 61830 data points in total.
In order to choose the hyper-parameter, we used the Cross Validation for time series to train the model. We tried the folds from 2 to 12, and finally chose 5 folds. The whole train-test scheme as shown below.
Model-XGBoost
In the model part, we tried several methods but they didn’t work, such as the multiple linear regression, logistic regression, SVM, decision tree, random forest regression and neural network.Finally, we chose the XGBoost model. The following plot shows the top 18 most important features from the model.

We implemented 2 approaches for XGBoost. One is that we trained the model using all training data at once, and optimize parameters for single model. In this way, we could get the result faster, but the final model may be not suitable for all data. In the experiment, we used 5 folds of time series and single grid search for parameter optimization. It took us 05 hours to train the model, and the results vary significantly by changing test set.
The other approach is training different ML model for each player and optimize parameters for each player.
This method is more intuitive, rational and flexible. However, this method will consume more time and computation. In the experiment, there are 2061 iterations in the training process. The timeseries fold iterations is 5 and the processing time is about 16 hours. In order to solve the time-consumption problem, we ran GridsearchCV and saved best parameters in a list and run models on test data from list. At last, the time consumption was reduced to 3 hours.
The following plot shows the result using different approaches.
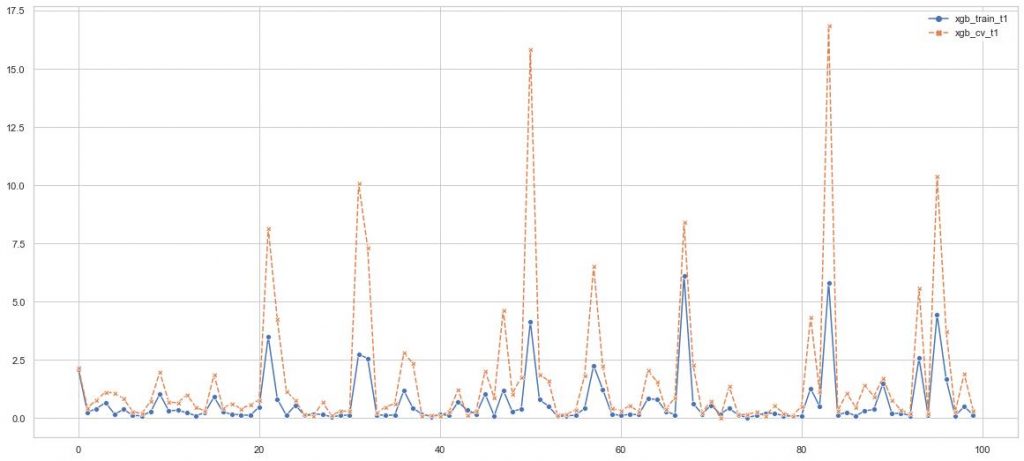
Final Results 代写商业分析论文
The final results are calculated on the sample test data (From April 1st, 2021 to 30th April, 2021). Below results are by using different model for each individual player:
| Target1 | Target2 | Target3 | Target4 | MCMAE | |
| MAE-Train | 0.75849 | 0.907261 | 0.499806 | 0.464482 | 0.65751 |
| MAE-CV | 1.12516 | 2.371943 | 1.296105 | 1.243742 | 1.509238 |
| MAE- Test | 1.014627 | 1.693665 | 1.266815 | 1.306911 | 1.320505 |
Conclusion 代写商业分析论文
The above approach to forecast engagement targets is successful. This approach can be used to forecast the 4 target. However, there are a lot to be improved in the future analysis.
Further Improvements
The following plots show the result of the prediction of 4 targets. We can find that there are some difference between two approaches. Based on the results, there are some improvement we could propose.
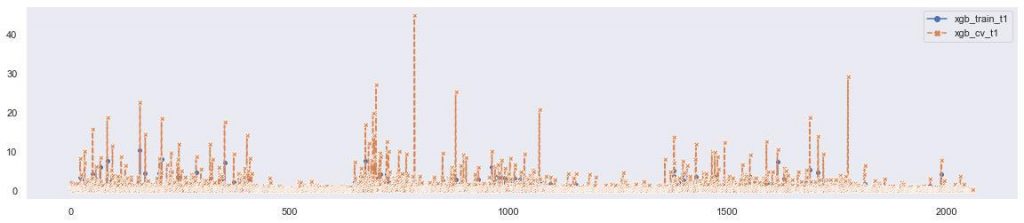
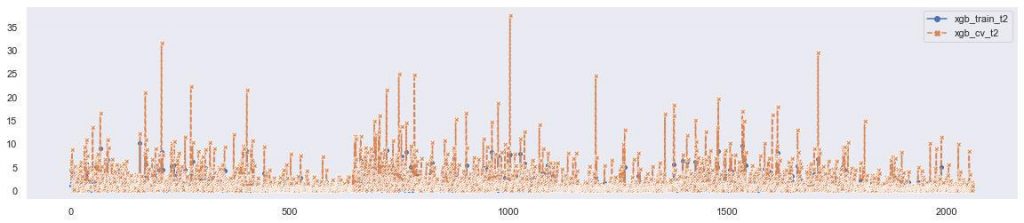
- Optimize individual player models, with less time.
- Identify trend in data of players withhigh MAE
- Identify features responsible forextreme MAE values
- Identify reason for players forapparent seasonality trend in data
- Adjust/drop troubling features orfind individual models for players with extreme features
更多代写:物理留学生代考 多邻国考试作弊 美国coursework代写 马拉西亚essay代写 论文代写范例 论文辅导
合作平台:essay代写 论文代写 写手招聘 英国留学生代写


