Quiz: Final Sample Exam
机器学习quiz代做 Below I have provided the instructions that accompany the actual exam so that you can prepare for the real exam.
Quiz Instructions
This is a sample exam that represents the types and difficulty of questions to be expected in the exam. It does not represent the length of the real exam.
Below I have provided the instructions that accompany the actual exam so that you can prepare for the real exam.
Final Exam Instructions:
- The final exam duration is 130 minutes (this includes 10 minutes of reading time).
- This is a restricted open book exam. You are allowed:
1.1x A4 one sided handwritten notes. 机器学习quiz代做
2.Multiple sheets of blank scratch paper and a pen/pencil.
3.A handheld calculator. All other electronic devices are not permitted.
3.Please read each questions carefully and then do any necessary derivation/calculation and answer each question.
- Marks are not equal for each question.
- Please type your answer with your own words in the online editable answer box.
- Necessary formulas are provided with the question.

Question 1
(5 marks) From a bias-variance tradeoff perspective explain why bagged ensembles require stronger models than boosted ensembles.
Question 2
(4 marks) Identify and describe two reasons why computer vision is challenging.
Question 3
(5 marks) In the context of matrix factorisation, identify and outline a technique to estimate the factor matrices W and H.
Question 4 机器学习quiz代做
(4 marks) In your own words, describe the cold start problem of recommendation systems and provide an example23/11/2021, 10:29
Question 5
(4 marks) In your own words, describe the purpose of bias units in a neural network
Question 6
(6 marks) Name an example of a recommendation system that you have personally experienced and describe how you the recommendation system can be posed as a Multi-Armed Bandits problem.
Question 7 机器学习quiz代做
(5 marks) Describe the operation of the Thompson Sampling Policy in the context of a Multi-Armed bandit model.23/11/2021, 10:29
Question 8
Suppose you are evaluating policies for the MAB environment with binary rewards.
Each bandit is Bernoulli distributed with the following parameters:
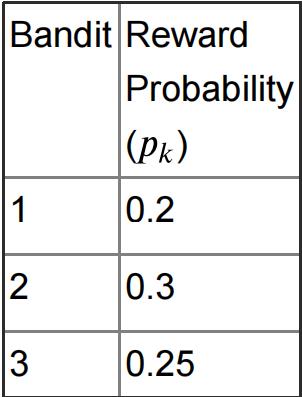
You have designed two policies and the action log is shown below:
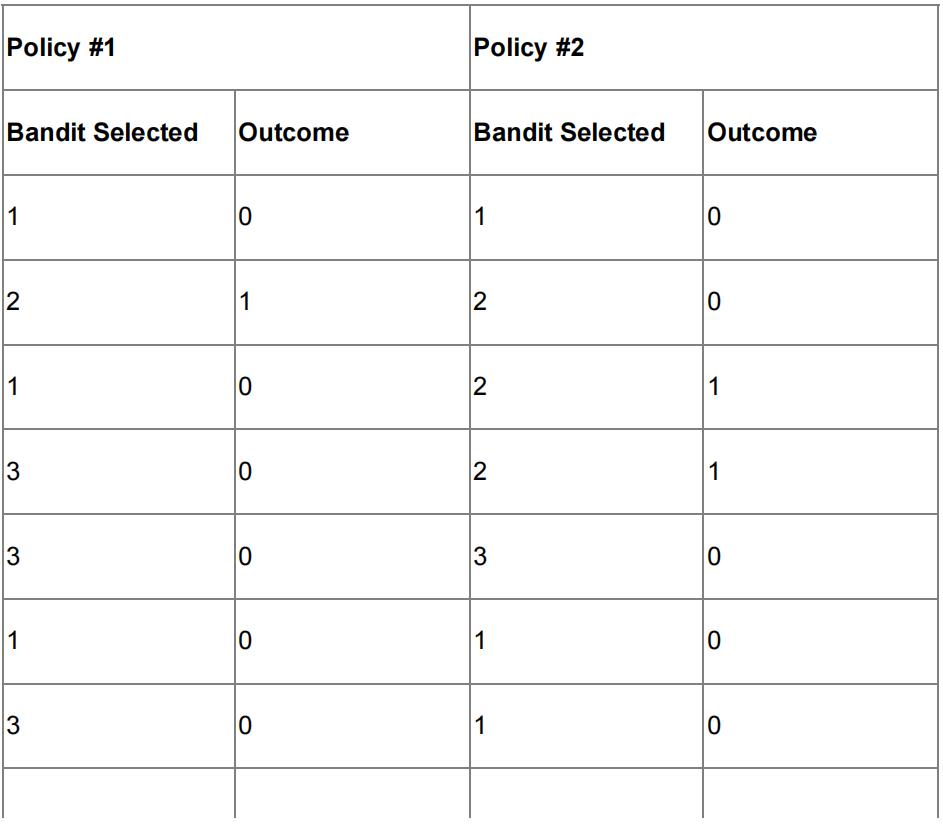
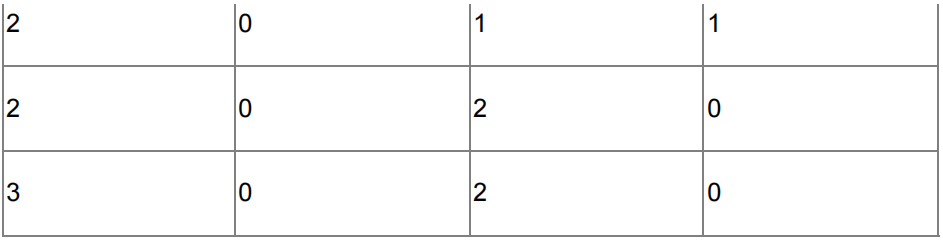
Answer the following:
- (6 marks) Select the policy which performs the best, explain your reasoning
- (4 marks) Can you conclude that one policy is superior to the other based on this run?
Question 9

(5 marks) Outline the steps of fitting an Adaboost model and match each step to the corresponding line/s in the code shown above.
更多代写:Online Course网课代修 网考代考 Python作业代修 report代写北美 澳大利亚essay论文代写 代写大学论文
合作平台:essay代写 论文代写 写手招聘 英国留学生代写



