Final Examination, Semester
COMP30027 Machine Learning
代考Machine Learning Answer each of the questions in this section as briefly as possible. Expect to answer each sub- question in a couple of lines.
Reading Time: 15 minutes. Writing Time: 2 hours. This paper has 7 pages including this cover page. Instructions to Invigilators:
Students should be provided with script books, and should answer all questions in the
provided script book. Students may not remove any part of the examination paper from the examination room.
Instructions to Students: 代考Machine Learning
There are 9 questions in the exam worth a total of 120 marks, making up 60% of the total assessment for the subject.
- Please answer all questions in the script book provided, starting each question on a new page. Please write your student ID in the space above and also on the front of each script book you use. When you are finished, place the exam paper inside the front cover of the script book.
- Your writing should be clear; illegible answers will not be marked.
Authorised Materials: No materials are authorised.
Calculators: Students are permitted to use calculators.
Library: This paper may be held by the Baillieu Library.
| Examiners’ use only | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Total |
Section A: Short Answer Questions [28 marks]
Answer each of the questions in this section as briefly as possible. Expect to answer each sub- question in a couple of lines.
Question 1: Short Answer Questions [28 marks]
1.What is the primary difference between “supervised” and “unsupervised” learning?[5 marks]
2.For each of the following features, indicate which of “numeric”, “ordinal”, and “categorical” best captures its type: [4marks]
(a)blood pressure level, with possible values {low, medium,high} 代考Machine Learning
(b)age, with possible values[0,120]
(c)weather, with possible values {clear, rain,snow}
(d)abalone sex, with possible values {male, female,infant}
3.Describe a strategy for measuring the distance between two data points comprising of “cat- egorical” features. [5marks]
4.What is the relationship between “accuracy” and “error rate” in evaluation? [5marks]
5.With the aid of a diagram, describe what is meant by “maximal marginal” in the context of training a “support vector machine”. [5marks]
6.What makes a feature “good”, i.e. worth keeping in a feature representation? How might we measure that “goodness”? [3marks]
7.Foreach of the following models, state whether it is canonically applied in a “classification”, “regression” or “clustering” setting: [6 marks]
(a)multi-layer perceptron with a softmax finallayer 代考Machine Learning
(b)soft k-means
(c)multi-response linearregression
(d)logistic regression
(e)model tree
(f)support vectorregression
8.With the aid of an example, briefly describe what a “hyperparameter” is. [3marks]
9.With the use of an example, outline what “stacking” is. [5marks]
10.What is the convergence criterion for the “EM algorithm”? [5marks]
11.Outline the basis of “purity” as a form of cluster evaluation. [5marks]
12.Whatis the underlying assumption behind active learning based on “query-by-committee”?[1.5 marks]

Section B: Methodological Questions [30 marks] 代考Machine Learning
In this section you are asked to demonstrate your conceptual understanding of a subset of the methods that we have studied in this subject.
Question 2: Random Forests [7 marks]
“Random forests” are based on decision trees under different dimensions of “randomisation”. With reference to the following toy training dataset, provide a brief outline of two (2) such “ran- dom processes” used in training a random forest. (You should give examples as necessary; it is not necessary to draw the resulting trees, although you may do so if you wish.)
| Instance ID | Feature 1 | Feature 2 | Feature 3 | Class |
| A: | 1 | 1 | 1 | True |
| B: | 0 | 2 | 0 | True |
| C: | 3 | 0 | 0 | False |
| D: | 1 | 1 | 2 | False |
| E: | 2 | 0 | 2 | False |
Question 3: HMMs [9 marks]
This question is on “hidden Markov models”.
- Inthe “forward algorithm”, αt(j) is used to “memoise” a particular value for each state j and observation t. Describe what each αt(j) represents. [3 marks]
- In the “Viterbi algorithm”, two memoisation variables are used describe for each combina- tion of state j and observation t: (1) βt(j) (which plays a similar role to αt(j) in the forward algorithm); and (2) ψt(j). Describe what each ψt(j) [3marks]
- Why do we tend to use “log probabilities” in the Viterbi algorithm but not the forward algorithm? [3marks]
Question 4: Model learning [14 marks] 代考Machine Learning
We have discussed that the objective in much of supervised machine learning is to derive a model that explains (“fits”) a set of (labelled) data. In a basic “curve fitting” scenario, we will assume that all of the needed data is available to us at the time of building the model; the objective is to fit a model to that data. In machine learning, in contrast, we have only a subset of possible data available to us when we build the model. This contrast has certain implications for how we approach machine learning, which we explore in this question.
Discuss the implications of knowing that we do not have all possible data for a given problem, in terms of the following aspects:
- Isour primary objective in machine learning to derive a model that fits the subset of the data that we do have? Why or why not? [3 marks]
- Explain how we can use our limited data, in a machine learning context, to demonstrate whether or not our objective has been met. [3marks]
- Identify and explain one important problem that can emerge with respect to this primary objective, even if we are successful in deriving a good model for the data that we have. Nameone specific technique discussed in class that can be applied to mitigate this problem, and explain how it does so. [3 marks]
- Define “bias” and “variance”, indicating how we might detect each one. Discuss how bias and variance relate to each other in the context of our primary objective. [5marks]
Section C: Numeric Questions [42 marks]
In this section you are asked to demonstrate your understanding of a subset of the methods that we have studied in this subject, in being able to perform numeric calculations. Questions 5 and 6 both make use of the following training data set:
| early | tie | label |
| N | Y | dinner |
| Y | N | tea |
| Y | N | dinner |
| N | N | dinner |
| Y | N | dinner |
| N | N | tea |
Table 1: Training Dataset for Questions 5 and 6
Question 5: Naive Bayes [9 marks]
Given the training dataset from Table 1:
- Usingthe method of “maximum likelihood estimation” (without smoothing), compute P (dinner) and P (dinner|tie = Y). [1.5 marks] 代考Machine Learning
- Apply the method of “Naive Bayes” as it was discussed in the lectures, to predict the label of the test instance {early=N, tie=N}; show your workings. [5marks]
Question 6: Decision Trees [15 marks]
- Briefly explain — in at most two sentences — the basic logic behind the “ID3” algorthmic approach toward building decision trees. This should be focussed on labelling the nodes and leaves; you do not have to explain edge-cases. [3marks]
- Thecriterion for labelling a node, as explained in the lectures, was based around the idea of “entropy” — what does entropy tell us about a node of a decision tree? [3 marks]
- A very similar alternative to entropy is the so-called GINI coefficient, defined as follows:
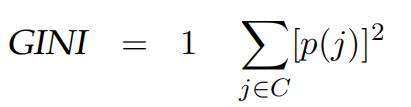
Calculate the GINI coefficient based on the labels in Table 1. [3 marks]
- Extend the notion of “Information Gain” to “GINI Gain”, and demonstrate why tiewould be chosen as the root of the decision tree on the given data. [3 marks]
- Why will the resulting decision tree have difficulty classifying test instances like{early=N,tie=N}? [3 marks]
Question 7: Nearest Prototype and k-Nearest Neighbour [10.5 marks] 代考Machine Learning
Given the following training dataset:
| abv | opacity | label |
| 4.8 | 0.20 | ale |
| 5.2 | 0.10 | ale |
| 5.0 | 0.33 | ale |
| 4.7 | 0.02 | lager |
| 5.1 | 0.23 | lager |
| 4.6 | 0.05 | lager |
- Generate the “prototype” for each class in the training data. [3marks]
- Forthe test instance abv=5.1, opacity= 0.23 , determine which of the prototypes is more (You will need to choose an appropriate metric, and show your work; do not just use inspection.) [3 marks]
- What should happen if we instead use the “1-Nearest Neighbour” method to predict the label of that test instance? (You do not need to show your work.) [5marks]
- Give one possible reason why each of these two methods could reasonably claim to bemak- ing a better prediction for this instance. [3 marks]
Question 8: Evaluation [7.5 marks]
Assume that our development set contains 100 instances (truly) labelled as one of three classes as follows: 50 acro instances, 30 base instances, and 20 claw instances. We then build a classifier, apply it to this dataset, and observe the following confusion matrix:
|
acro |
Actual
base |
claw |
|
| acro | 28 | 5 | 7 |
| Predicted base | 10 | 10 | 0 |
| claw | 0 | 8 | 12 |
1.Determine the “classification accuracy” of the system described above. [5marks]
2.Calculate the “micro-averaged precision” and “macro-averaged precision” of this system. (Show your workings; you should simplify these to a single fraction or decimal value.) [3 marks]
3.Insome contexts these three values are equal; here they are Briefly explain why. [3 marks]
Section D: Design and Application Questions [20 marks] 代考Machine Learning
In this section you are asked to demonstrate that you have gained a high-level understanding of the methods and algorithms covered in this subject, and can apply that understanding. Expect to respond using about one-third of a page to one full page, for each of the three points below. These questions will require significantly more thought than those in Sections A–C and should be attempted only after having completed the earlier sections.
Question 9: [20 marks]
You are tasked with building a system which labels images as to whether they contain a given product type (e.g. car or mobile phone), based on a large set of labelled training instances. A given image may contain multiple or no product types, with the expectation that most (but not all) test instances will contain at least one product.
Each image has been transformed into an “embedding” (i.e. a dense real-valued vector represen- tation of the image). This transformation process should be treated as a “black-box”, which will be applied consistently to every image in the collection.
At the start of the project, you are provided with training instances for each of 500 product types, but as the project progresses, the set of product types is to be expanded in increments of around 100 new types, and new training instances are to be provided for each of the newly-added product types, up to a final total of around 1000 product types. 代考Machine Learning
You will additionally be provided with extra training instances for a subset of the pre-existing product types, e.g. to capture newly-released models of cars or mobile phones. However, it is desirable to have a model that does not reverse positive predictions for a pre-existing category; rather, you are instructed to employ this extra training data to find further instances of the corre- sponding product type.
Finally, for each product type, you are provided with a “priority level” (high, medium or low) for how critical it is that your model has good coverage in correctly identifying instances of that product type.
Outline the following:
- the type of machine learning algorithm that you will use, and why; state any assumptions you are making in your answer.
- how you will deal with updates to the label set and also extra training instances for pre- existinglabels, making specific mention of how you will maintain consistency in your model predictions, but still have your model find new instances of a given product type.
- how you will evaluate your model.
x««««««« End of Exam »»»»»»»x
Library Course Work Collections
Author/s:
Computing and Information Systems
Title:
Machine Learning, 2017 Semester1, COMP30027
Date:
2017
更多代写:物理代上网课推荐 多邻国代考 温哥华哲学代考 理工类申请文书代写 历史学essay论文代写 代写作业
合作平台:essay代写 论文代写 写手招聘 英国留学生代写



