COMS 4771 HW1 (Spring 2022)
Due: Feb 18, 2022 at 11:59pm
代写机器学习 Youwant to estimate the coin’s What is the Maximum Likelihood Estimate (MLE) ˆb given the observations x1, . . . , xn?
This homework is to be done alone. No late homeworks are allowed. To receive credit, a type- setted copy of the homework pdf must be uploaded to Gradescope by the due date. You must show your work to receive full credit. Discussing possible approaches for solutions for homework ques- tions is encouraged on the course discussion board and with your peers, but you must write their own individual solutions and not share your written work/code. You must cite all resources (includ- ing online material, books, articles, help taken from/given to specific individuals, etc.) you used to complete your work.
1 Maximum Likelihood Estimation (MLE) versus Maximum a Posteriori (MAP) Estimation 代写机器学习
Here we investigate the difference between MLE vs. MAP estimation using a specific example. Your friend gives you a coin with bias b (that is, tossing the coin turns ‘1’ with probability b, and turns ‘0’ with probability 1 − b). You make n independent tosses and get the observation sequence x1, . . . , xn ∈ {0, 1}.
(i)Youwant to estimate the coin’s What is the Maximum Likelihood Estimate (MLE) ˆb given the observations x1, . . . , xn?
(ii)Is your estimate from part (i) an unbiased estimator of b? How about consistent? Justifyyour answer.
(iii)Derive a simple expression for the variance of thiscoin?
(iv)What is the MLE for the coin’svariance? 代写机器学习
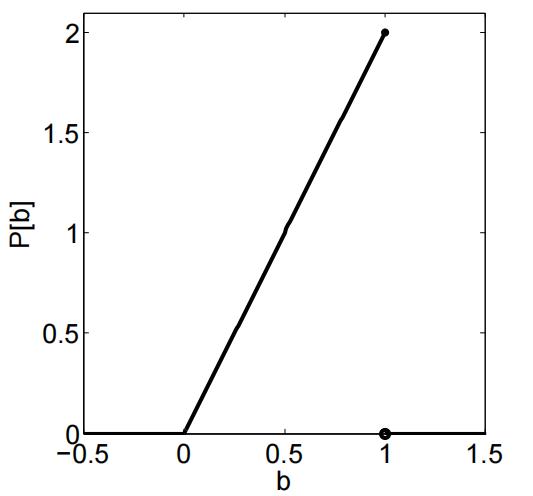
(v)Yourfriend reveals to you that the coin was minted from a faulty press that biased it towards 1. Suppose the model for the faulty bias is given by the following distribution: Having this extra knowledge, what is the best estimate for the coin’s bias b given the observation sequence? That is, compute: arg maxb P [b | x1, . . . , xn].
Note: this estimate of the coin’s bias encorporates prior knowledge, and is call a MAP esti- mate.
(vi)When does MAP estimate equalsMLE?

2 On Forecasting Product Demand 代写机器学习
One way retail industry uses machine learning is to predict how much quantity Q of some product to they should buy to maximize their profit. The optimal quantity depends on how much demand D there is for the product as well as its cost for the retailer to buy C and its selling price P to the customer. Assuming that the demand D is distributed as P (D), we can evaluate the expected profit considering two cases:
- if D ≥ Q, then the retailer sells all Q items and make a profit π = (P −C)Q.
- butif D < Q, then the retailer can only sell D items at profit (P C)D, but has lost C(Q D)
on unsold items. 代写机器学习
- What is the expected profit if the retailer buys Q items? Simplify the expression as much as possible.
- Bytaking the derivative (wrt Q) of the above expression for expected profit, show that the optimal quantity Q∗ to by satisfies Q∗ = F −1(1 − (C/P )), where F is the cdf of D. That is, the optimal Q∗ is when the cumulative density (of D) equals 1 − (C/P ).
3 Bayes Error Rate
Consider the classification problem on an arbitrary (measurable) input space X and a binary output space Y ={0, 1}. Given a joint data distribution D over X × Y , let g : X → Y denote the Bayes classifier g(x) := arg maxY Pr[Y X = x]. Define ERR(g) := Pr(x,y)∼D[g(x) = y] as the error rate of the Bayes classifier. Prove the following statements about the error rate of g.
(i)Prove that
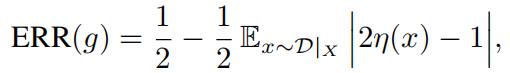
where D|X denotes the marginal distribution on X, and η(x) := P [Y = 1|X = x].
(ii)Let p1:= Pr[Y = 1], then
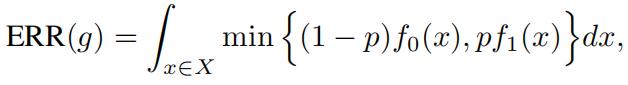
where f1 and f0 are densities of the class conditional distributions Pr[X Y = 1] and Pr[X Y = 0] respectively.
(iii)Ifthe class priors are equal (that is, Pr[Y = 0] = Pr[Y = 1] = 1/2), then
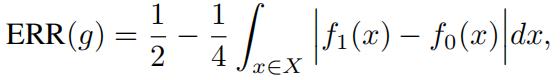
where f1 and f0 are densities of the class conditional distributions Pr[X Y = 1] and Pr[X Y = 0] respectively.
4 A comparative study of classification performance of hand- written digits
Download the datafile digits.mat. This datafile contains 10,000 images (each of size 28×28 pix-els = 784 dimensions) of handwritten digits along with the associated labels. Each handwritten digit belongs to one of the 10 possible categories 0, 1, . . . , 9 . There are two variables in this datafile: (i) Variable X is a 10,000×784 data matrix, where each row is a sample image of a handwritten digit.
(ii)Variable Y is the 10,000×1 label vector where the ithentry indicates the label of the ith sample image in X.
Special note for those who are not using Matlab: Python users can use scipy to read in the mat file,R users can use R.matlab package to read in the mat file, Julia users can use JuliaIO/MAT.jl. Octave users should be able to load the file directly. 代写机器学习
To visualize this data (in Matlab): say you want to see the actual handwritten character image of the 77th datasample. You may run the following code (after the data has been loaded):
figure;
imagesc(1-reshape(X(77,:),[28 28])’); colormap gray;
To see the associated label value:
Y(77)
(i)Create a probabilistic classifier (as discussed in class) to solve the handwritten digit classi- fication problem. The class conditional densities of your probabilistic classifier should be modeled by a Multivariate Gaussian distribution. It may help to recall that the MLE for the parameters of a Multivariate Gaussianare:
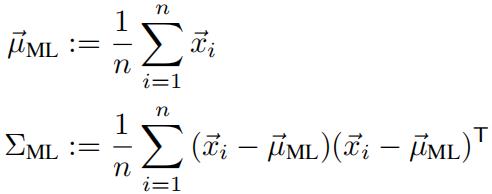
You must submit your code to receive full credit.
(ii)Create a k-Nearest Neighbor classifier (with Euclidean distance as the metric) to solve the handwritten digit classification problem.
You must submit your code to receive full credit. 代写机器学习
(iii)Whichclassifier (the one developed in Part (i) or the one developed in Part (ii)) is better? You must justify your answer with appropriate performance graphs demonstrating the superiority of one classifier over the other. Example things to consider: you should evaluate how the classifier behaves on a holdout ‘test’ sample for various splits of the data; how does the training sample size affects the classification
(iv)As discussed in class, there are several metrics one can use in a Nearest Neighbor classifica- tion. Do a similar analysis to justify which of the three metrics: L1, L2or L∞ is better for handwritten digit classification problem.
Note: All plots, analysis and results for this question should be included in the pdf document to receive credit.
更多代写:机械工程代写 雅思代考 business model怎么写 apa格式范文 argumentative essay怎么写 sci论文代写费用
合作平台:essay代写 论文代写 写手招聘 英国留学生代写