ECO00041 Time Series Exercise Set 1 (10%) Autumn 2019
代写时间序列作业 where ut ~ iidN (0,σ2u). Discuss if the testing procedures derived in (b) and (c) are still valid. If not, explain how to do a valid inference.
1.(a) Are the following stochastic processes covariance-stationary?
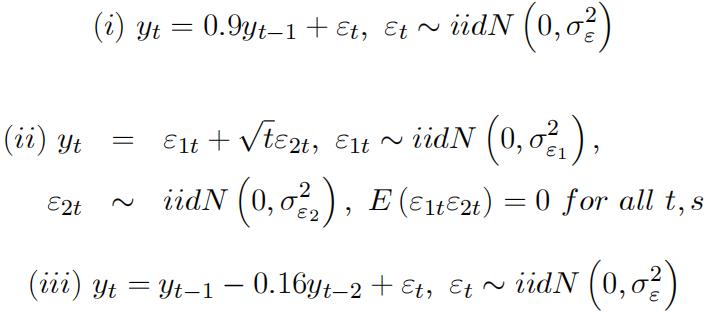
(b) Derive their autocorrelation and partial autocorrelation functions and comment on the results.
2.(a) Consider the stationary AR(fi) process, 代写时间序列作业
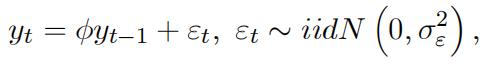
and derive autocorrelation functions given by
gs = Øs, s = 0, 1, 2, …
Draw the correlograms for $ = (0.8, 0.†, 0.£} and comment on the results.
(b)Show that random walkprocess,
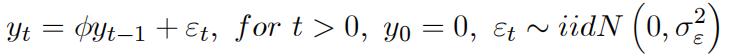
does not satisfy the stationarity condition. Next, show that the ACF‘s for the random walk process is given by
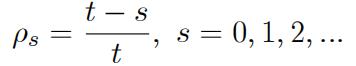
(c)What type of stylised facts can you observe by comparing the correlogramsfor stationary and nonstationary Describe a few reasons that it is important to distinguish between the difference- stationary and the trend-stationary process.

3.Consider the AR(fi) regression with anintercept: 代写时间序列作业
yt = α + Øyt—1 + εt, t = 1, …, T,
where yt is a scalar variable, α and $ are unknown parameters, andεt ~ iidN (0, σ2u ). We assume that the initial value yO is fixed.
(a)Derive the OLS estimator of Ø and its asymptotic distribution when |Ø| < 1.
(b)Explain how to test HO: Ø = ØO against H1 : Ø= ØO under|ØO| < 1.
(c)Describe how to test HO: Ø = 1 against H1 : Ø < 1
(d)Suppose that εtis now serially correlated as
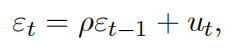
where ut ~ iidN (0,σ2u). Discuss if the testing procedures derived in (b) and (c) are still valid. If not, explain how to do a valid inference.
4.(a) Consider the AR(1)process,
yt = α +Øyt—1 + ut, t = 1, …, T,
where ut ~ iid(0,σ2u). Let
yT +h : unknown value of y in future period T + h, h = 1, 2, …
![]() +h: forecast of yT +h made on the basis of information available at time T, 代写时间序列作业
+h: forecast of yT +h made on the basis of information available at time T, 代写时间序列作业
eT +h = yT +h — yT +h : forecast error.
Then, show that as h →∞
and comment on these results.
(b) Suppose that $ = fi. Then what do you get for yT +h
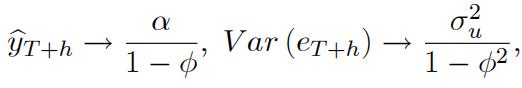
and Comment on your findings.
5. A research uses a sample of 200 observations on yt, the number (in 1000s) of unemployed persons, to model the time series behavior of the series and to generate predictions. First, she computes the sample autocorrelation functions with the following results: 代写时间序列作业
| s | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| g^s | 0.83 | 0.45 | 0.6 | 0.45 | 0.44 | 0.35 | 0.29 | 0.2 | 0.11 | -0.01 |
(a)Whatdo you mean by the sample autocorrelation functions? Does the above pattern indicate that an AR or an MA representation is more appropriate? Why?
Next, the sample partial autocorrelation functions are obtained as:
| s | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| SP ACFs | 0.83 | 0.16 | -0.09 | 0.05 | 0.04 | -0.05 | 0.01 | 0.1 | -0.03 | -0.01 |
(b)What do you mean by the sample partial autocorrelation func- tions? Why is the first PACF equal to the first older ACF? Does the above pattern indicate that an AR or an MA representation is more appropriate?Why?
The researcher decides to estimate, as a first attempt, an AR(1) model: 代写时间序列作业
yt = α + Øyt—1 + εt
and obtained the estimate, Ø^1 = 0.83 with a standard error of 0.07.
(c)Whichestimation method is appropriate for estimating an AR(1) model? Explain under which conditions it is consistent and effcient.
(d)Perform the test for the null hypothesis, Ø =9.
(e)Perform the unit root test based on the above regression results. Next, the researcher extends the model to AR(2) regression withthe following results (standard errors in parenthesis):
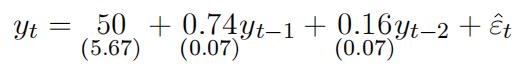
(f)Would you prefer AR(2) model to the AR(1) model? How would you check whether ARMA(2,1) may be moreappropriate?
(g)What do the above estimation results tell you about the validity of the unit root test conducted in (e)? Then how would test for a unit root in the AR(2)model?
(h)Supposethat the last two quarterly unemployment levels for 1996Q3 and 1996Q4 were 550 and 600. Evaluate the predictions for 1997Q1 and 1997Q2. Can you say anything sensible about the predicted values for 2023Q1(and its accuracy)?
6.Consider the following simple relationship between aggregatesavings St and aggregate income Yt: 代写时间序列作业
St = α + βYt + εt, t = fi, …, T.
For some country this relationship is estimated by OLS over the years 1956-2005 (T = 50). The results are given below:
| Variable | Coefficients | Standard error |
| Constant | 38.90 | 4.57 |
| Y | 0.098 | 0.009 |
o^ = ££.†F, RX = 0.93, DW = 0.70
where o^ is the standard error of regression, R2 is the multiple correla- tion coefficient, and DW is the Durbin-Watson statistic.
(a)How would you interpret the coefficient of 0.098 onincome?
(b)Explain why the result indicate that there may be a problem of positive autocorrelation. Can you give arguments why in economic models positive autocorrelation is more likely than negativeone? 代写时间序列作业
(c)Whatare the effects of autocorrelated residuals on the BLUE prop- erty of the OLS estimator?
Now we assume that both S and Y are nonstationary I(1) series.
(d)Isthere any indication that the relation between them is spurious?
(e)Describe two different tests that can be used to test the null hy- pothesis that S and Y are not
(f)Arethere reasons to correct for autocorrelation in errors when we estimate a cointegrating regression?
7.Short essayquestions 代写时间序列作业
(a)The Box and Jenkins three-stage ARMA(p, q) modelling.
(b)Describe and compare the DF test and the KPSS test.
(c)Givean example from Economics or Finance where cointegration among a set of variables may be Explain, by reference to the implication of no-cointegration, why cointegration between the series might be expected. For example, describe a cost of carry model for cash and futures price indexes.
Notes: The first in-course exercise (10%) will be downloadable from VLE on Monday fi4 October, and one anonymous copy of this assignment (only with your exam number) must be submitted to the Economics reception desk no later than 3PM on Wednesday 30 October. Handwritten reports are accepted. Failure to meet this initial deadline will result in a reduc- tion of marks (please see VLE for details). Faxed or emailed copies of the assignment will not be accepted.
更多代写:计算机代修网课 gre在家考作弊 大学社会心理学代写 补充文书代写 波士顿留学生essay论文代写 如何写文献综述
合作平台:essay代写 论文代写 写手招聘 英国留学生代写